

Every web developer knows the importance of choosing a suitable database for building modern apps. Even though NoSQL, NewSQL, and other types of databases have received a great deal of buzz in the last few years, relational database management systems (or RDBMS) are still relevant for several critical business use cases and will likely do so in the foreseeable future. Among the many open-source relational databases available, PostgreSQL is a popular choice among developers. It was named DBMS of the year in 2020 by DBEngines, and with every release of PostgreSQL new features are available making it easy for developers and administrators to run their apps.
This blog will highlight some key features of the newly available PostgreSQL 14, which every developer can benefit from. So, let's dive right in.
Complex data type support
JSON subscripting
PostgreSQL continues to add innovations for complex data types, making JSON data more accessible. In postgreSQL 14, developers can use subscripts to iterate through JSON key pairs and fetch corresponding values. For example, using this capability, nested JSON fields can be quickly traversed to retrieve values to reconstruct application objects.
1select (
2 '{ "PostgreSQL": { "release": 14 }}'::jsonb
3)['PostgreSQL']['release'];
4
5 jsonb
6-------
7 14
8
Working with disjointed data ranges
In the real world, data ranges are pretty common. For example, if you have sensor readings going into a PostgreSQL database, you may want to define a range for low, medium, and high metrics. Before version 14, you could set data ranges for integers, numerics, timestamps, and other data types. However, these ranges had to be contiguous, and it required multiple insert records across the different ranges. In PostgreSQL 14, a single insert statement can be used to map data across multiple noncontiguous ranges. Let's check it out with an example.
First, create an enum data type to capture low, medium, and high sensor reading levels.
1create type valid_levels as enum ( 2 'low', 'medium', 'high' 3); 4
To store sensor reading metric data, create a table consisting of the sensor description, the level and the range of timestamps when the sensor was at that level.
1create table sensor_range (
2 reading_id serial primary key,
3 metric_desc varchar(100),
4 metric_level valid_levels,
5 metric_ts tsmultirange
6);
7
Now, insert some data into the table. Note that, the insert statement below provides two time ranges that are not contiguous.
1insert into sensor_range ( 2 metric_desc, 3 metric_level, 4 metric_ts 5) 6values ( 7 'Temperature', 8 'high', 9 '{[2021-11-01 6:00, 2021-11-01 10:00],[2021-11-05 14:00, 2021-11-05 20:00]}' 10); 11 12insert into sensor_range ( 13 metric_desc, 14 metric_level, 15 metric_ts 16) 17values ( 18 'Temperature', 19 'low', 20 '{[2021-11-01 10:00, 2021-11-01 12:00],[2021-11-05 21:00, 2021-11-05 22:00]}' 21); 22
Query the data in the table to see the inserted data rows
1select *
2from sensor_range;
3
1| `reading_id` | `metric_desc` | `metric_level` | `metric_ts` |
2|--------------|---------------|----------------|-----------------------------------------------------------------------------|
3| 1 | Temperature | high | {[2021-11-01 6:00, 2021-11-01 10:00],[2021-11-05 14:00, 2021-11-05 20:00]} |
4| 2 | Temperature | low | {[2021-11-01 10:00, 2021-11-01 12:00],[2021-11-05 21:00, 2021-11-05 22:00]} |
5
Improved performance and monitoring
Query pipelining
If you're a developer accessing PostgreSQL using a high-level programming language, the database driver you're using is likely based on a C library called libpq. For example, suppose your application performs several write operations within a short period, or your network has a higher latency. In that case, you may want to fire off several queries over the same network connection simultaneously, so you don't have to wait for a reply after each query. Under the hood, libpq can send multiple queries to PostgreSQL while maintaining a queue of queries that are waiting for results. This queue consumes additional memory on both the client and server. Developers can now take advantage of PostgreSQL 14's client-side query pipeline mode using clients built on top of the latest libpq library to accelerate app performance.
Aside from query pipelining, the latest PostgreSQL 14 release brings several other enhancements to query parallelism, including improved performance of parallel sequential scans, parallel query execution capabilities for Foreign Data Wrappers, and the ability to run parallel queries when refreshing materialized views. With this, your PostgreSQL server can now do more work for you at a lower cost.
Monitoring and troubleshooting queries
Ask any database troubleshooting expert, and they will tell you that without a way to correlate data across different database components, investigating and monitoring query-related issues can quickly become a nightmare. When it comes to PostgreSQL, the SQL statement’s query_id can be used for this purpose, allowing database experts an easy way to identify workload patterns quickly, detect rogue run-away or slow queries, and common query-related issues. Before PostgreSQL 14, this information was only available using the pg_stat_statements extension, which shows aggregate statistics about queries that have finished executing, but now this information is additionally available for live running queries with pg_stat_activity, in the EXPLAIN VERBOSE statement, and log files. An example of using query_id IN EXPLAIN (VERBOSE) statement
Start by altering the system to enable the query_id
1alter system set compute_query_id = 'on';
2
Restart the PostgreSQL database for the alter system statement to take effect.
Run the following query that selects schema and table names from the catalog tables
1explain (verbose, costs off)
2select schemaname, tablename
3from pg_tables, pg_sleep(5)
4where schemaname <> 'pg_catalog';
5
View the result of the EXPLAIN statement
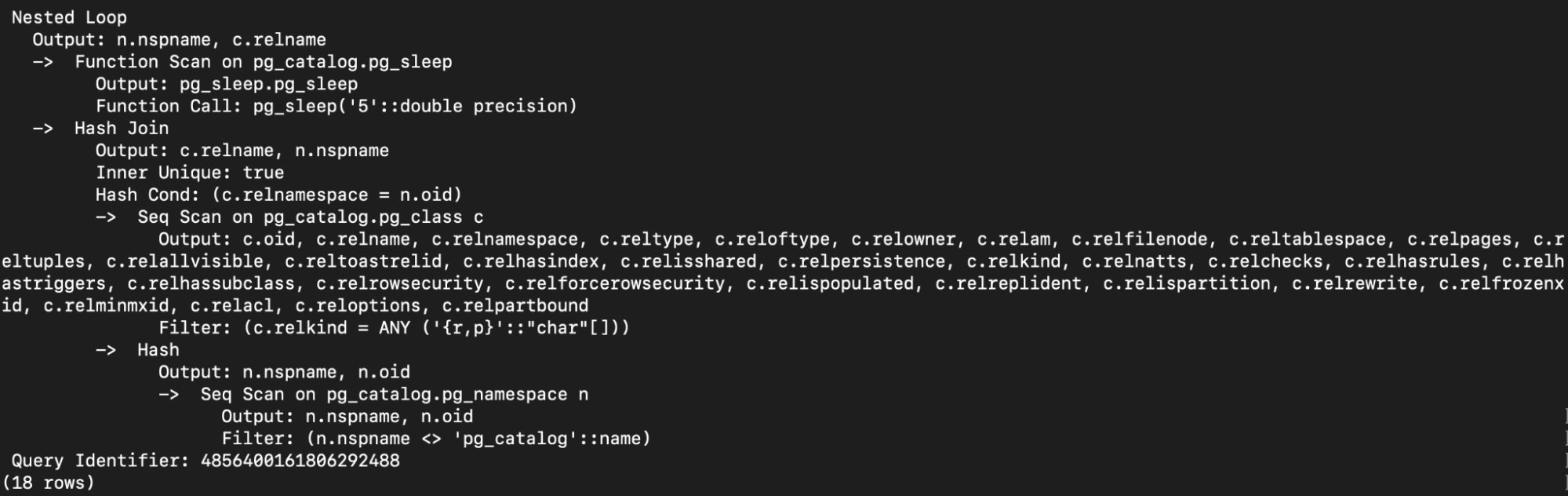
Notice that the query identifier is in the output:
Query Identifier: 4856400161806292488
Enhanced security
Security remains top of mind for every organization, and PostgreSQL 14 brings some critical enhancements in this area.
Have you ever wanted to manage database user access so that only specific individuals have read-only access? For example, consider a situation where you would like to host some sample data online for a demo and not allow demo users to modify or delete data. With the latest PostgreSQL version 14, you can easily set that up using a single GRANT statement.
1grant pg_read_all_data to bobfries; 2
From an authentication perspective, if you're still managing passwords in the database without third-party login providers, you may want to read this. Since version 10, PostgreSQL supports several different hashing mechanisms such as MD5 and SCRAM-SHA-256 to store user passwords on disk. However, to keep up with the latest security weaknesses around MD5 and meet regulatory compliance requirements, PostgreSQL 14 has made SCRAM-SHA-256 the default password management mechanism. So, if you are using old PostgreSQL client software, you may want to update it, to be able to connect to the newer versions of the database server.
It's only the tip of the iceberg
Indeed, there's a lot more to explore in the latest PostgreSQL, and we've barely scratched the surface of what PostgreSQL 14 has to offer. There's no better way to experience some of these features than by trying them out for yourself. You can check out these new features within your Supabase project without having to perform a local installation.
Explore the Supabase dashboard now and get started with your new project.